
To one who is unfamiliar with the concept, machine learning might sound like a complicated mechanism of training machines to do something. Although this vague definition is somewhat true, it boils down to statistics, and some programming to run calculations. If we double back and have a look at some formal definitions of machine learning you will find the below after a quick Google search.
“The use and development of computer systems that are able to learn and adapt without following explicit instructions, by using algorithms and statistical models to analyse and draw inferences from patterns in data.”
So, we can see the keywords here are statistics, computer systems and without following instructions (i.e., automation).
IBM tries to define machine learning as,
“Machine learning is a branch of artificial intelligence (AI) and computer science which focuses on the use of data and algorithms to imitate the way that humans learn, gradually improving its accuracy”
This second definition presents the wider concept of AI. In short, AI is the science of mimicking human intelligence, or more broadly animal intelligence. However, we will leave the discussion of AI in detail for a future article. Another key characteristic of machine learning is the gradual increase in accuracy. If you guessed that we use an iterative approach to achieve this ‘gradual improvement’, yes, you guessed right!
Before we move on to the different types of machine learning and go through some examples, let us summarise what we know about machine learning or ML. ML is a process we use with the goal of mimicking intelligence, to draw patterns from data without data-specific instructions. ML is also powered by a lot of statistics and probability.
The tree of ML
Machine learning algorithms can be categorised into 3 main branches. We will now introduce these briefly.
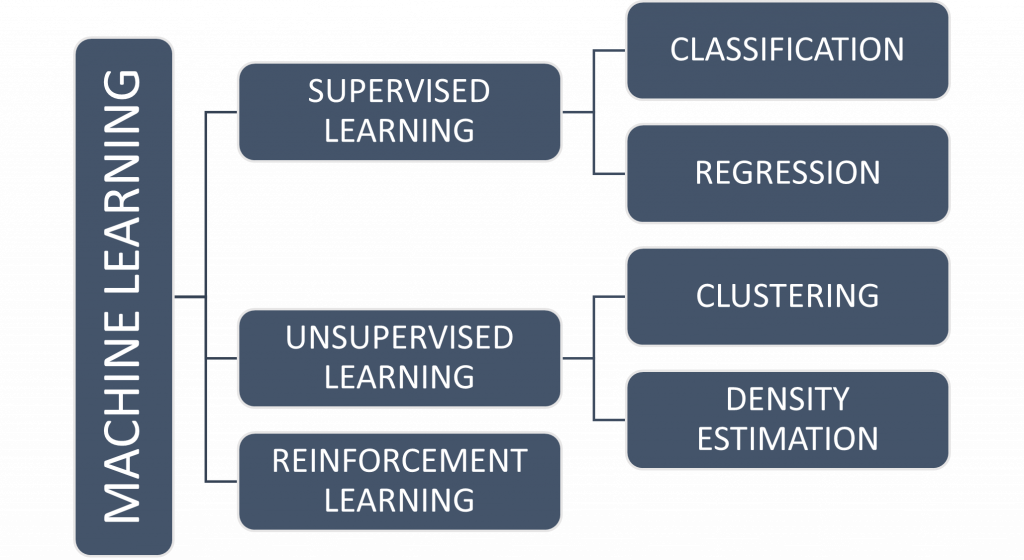
Supervised learning
Supervised learning is the branch of machine learning where a data set including the features and the target values is used to train a model. The idea is for this developed model to predict the target value for a new set of data. The ability of a model to predict these target values is referred to as its ability to generalise.
A very simple example for this could be predicting the income of a person using age and number of qualifications, age, gender. We would need to start with a data set of known people Including the target variable (income) and features (age, number of qualifications, gender). The number of features could be in the thousands and the target could be a categorical variable (classification problem) or a continuous variable (regression problem)
Unsupervised learning
In unsupervised learning, we do not have a training dataset, to begin with. Instead, we use properties (features) of the data to identify patterns. The underlying objective is to cluster similar data points together. For example, we may have the weight, age and breathing rate (i.e., features of the dataset) for a set of lab mice. We may know that there are some mice with diabetes and some healthy mice. However, we only have the features with us. We do not know which mice are diabetic and which are not. We can use a clustering algorithm to try and cluster the data points. This may enable us to separate the mice into two groups. With a sample of known mice in the dataset, we may be able to identify each cluster as diabetic or non-diabetic.
Clustering methods use various distance measures or alternatively probability distributions to identify and cluster similar data points.
Reinforcement learning
This type of ML algorithm works based on rewarding good behaviour and penalising bad behaviour. The objective is to get the agent that is being trained to seek the overall maximum reward. This may sound abstract, so let’s look at an example.
We train an agent (i.e., a program) to play chess against an opponent. Assume the opponent is quite skilled. So, the first time, the agent is beaten in a short number of steps. Now with the previous information, we get the agent to play the game again. We repeat this process until the agent improves to a level that is comparable to the highly skilled opponent. If a particular set of moves results in a win, then the agent’s reward is increased. If not, the agent is penalised. The opponent is usually the agent itself. And as the agent plays against itself perhaps thousands or even millions of games of chess, it becomes a true master. The agent here attempts to learn such that the long-term reward is maximised which translates to a high ability for the agent to beat a formidable opponent.
This brings us to the end of our basic introductory article on machine learning. We’ve discussed the main types of ML, and gone through a non-technical introduction for supervised, unsupervised and reinforcement learning. Await a deeper dive into some of these methods in our next articles. Until then, thanks for reading!



{kind=link}